Agent autonomy is not a single permission.
It is a sequence of action-level decisions.
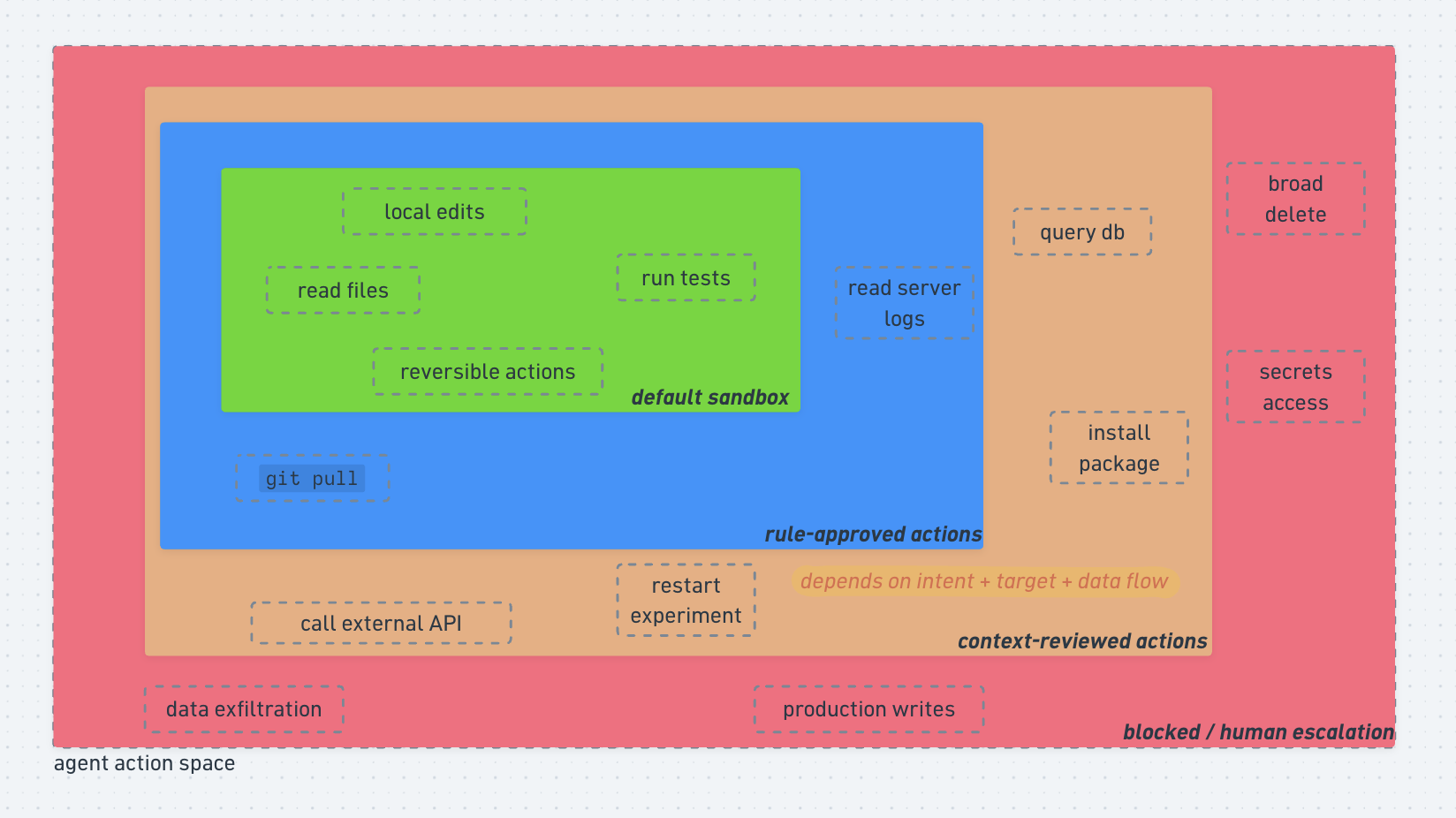
A coding agent works inside an environment. Some actions are low risk: reading files, editing local code, running tests. If something goes wrong, the damage is usually limited and reversible.
Other actions are different.
Querying a database. Installing a package. Calling an external API. Reading server logs. Restarting an experiment. Touching secrets. Writing to production.
These actions should not all be treated the same.
The naive version is binary:
Ask the human every time.
Or give the agent full access.
Both are bad.
If the agent asks too often, the user gets tired and approval becomes noise. If the agent gets full access, one bad action can become expensive.
The better version is layered.
Some actions can run by default because they stay local.
Some actions can be allowed by rules because they are known and narrow.
Some actions need review because safety depends on context.
Some actions should be blocked or escalated because the downside is too large.
That is the real design space.
Autonomy does not come from removing the boundary.
It comes from making the boundary smarter.
A good boundary does not ask:
“Should we trust this agent?”
It asks:
“Should this specific action be allowed here?”
That question is smaller, but much more useful.
For example, git pull can be rule-approved. A database query may need context. Reading files in the workspace can be allowed by default. Sending data to an external endpoint should probably be blocked or escalated.
The more actions the system can classify correctly, the more useful the agent becomes.
Not because we trusted it blindly.
Because we gave it the right kind of permission.